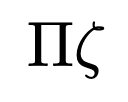
Gradient Descent
Gradient Descent is the backbone of optimization and deep learning. In this blog post, we dig into the math behind gradient descent, Polyak's heavy ball method, and Nesterov's accelerated gradient descent method. We perform these methods on an example function and see them in action!